Why do latest language transformers (LLMs like ChatGPT etc.) use reinforcement learning (RL) for finetuning instead of regular supervised learning (SL)? There are at least 5 reasons … [1/10] View Tweet
First of all, the question naturally arises because the RL paradigm (RLHF, RL with human feedback) involves labels to train a reward model. So why not using these labels directly with SL to finetune the model? [2/10] View Tweet
Reason 1). In SL, we usually minimize the diff between true labels and model outputs. The labels are the ranking scores of the responses to certain prompts. So, regular SL would tune a model to predict ranks, not responses. In fact, that’s how the reward label is trained. [3/10]
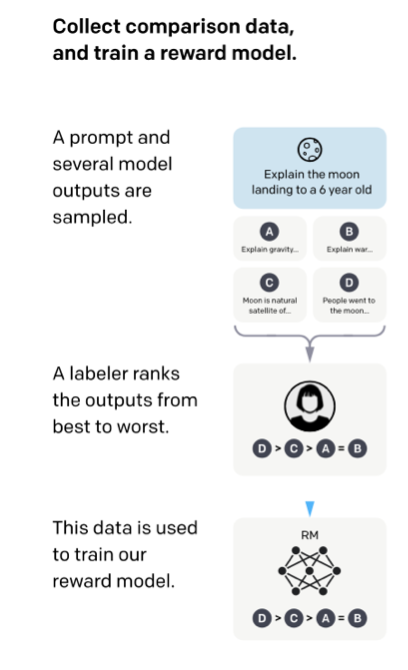 View Tweet
View TweetReason 2). Ok, so why don’t we reformulate the task into a constrained optimization problem so that we have a combined loss consisting of an “output text loss” and a “reward score” term that we optimize jointly with SL? [4/10] View Tweet
Sure, the above-mentioned constrained optimization would work if we want the model to generate correct Q & A pairs. But ChatGPT should have coherent conversations, so we need cumulative rewards as well. [5/10] View Tweet
Reason 3). Coming back to the token-level loss for SL mentioned above: in SL, we optimize the loss via cross-entropy. If we change individual words (tokens), due to the sum rule, this would only have small effects on the overall loss for a text passage. [6/10] View Tweet
Reason 4). Now, it’s not impossible to train the model with SL. In fact, that’s been done in the “Learning to Summarize from Human Feedback (2022)” paper. It just doesn’t perform that well compared to RL with human feedback. [8/10] View Tweet
Empirically, RLHF tends to perform better than SL. SL uses a token-level loss (that can be summed or averaged over the text passage), RL is taking the entire text passage, as a whole, into account. [9/10]
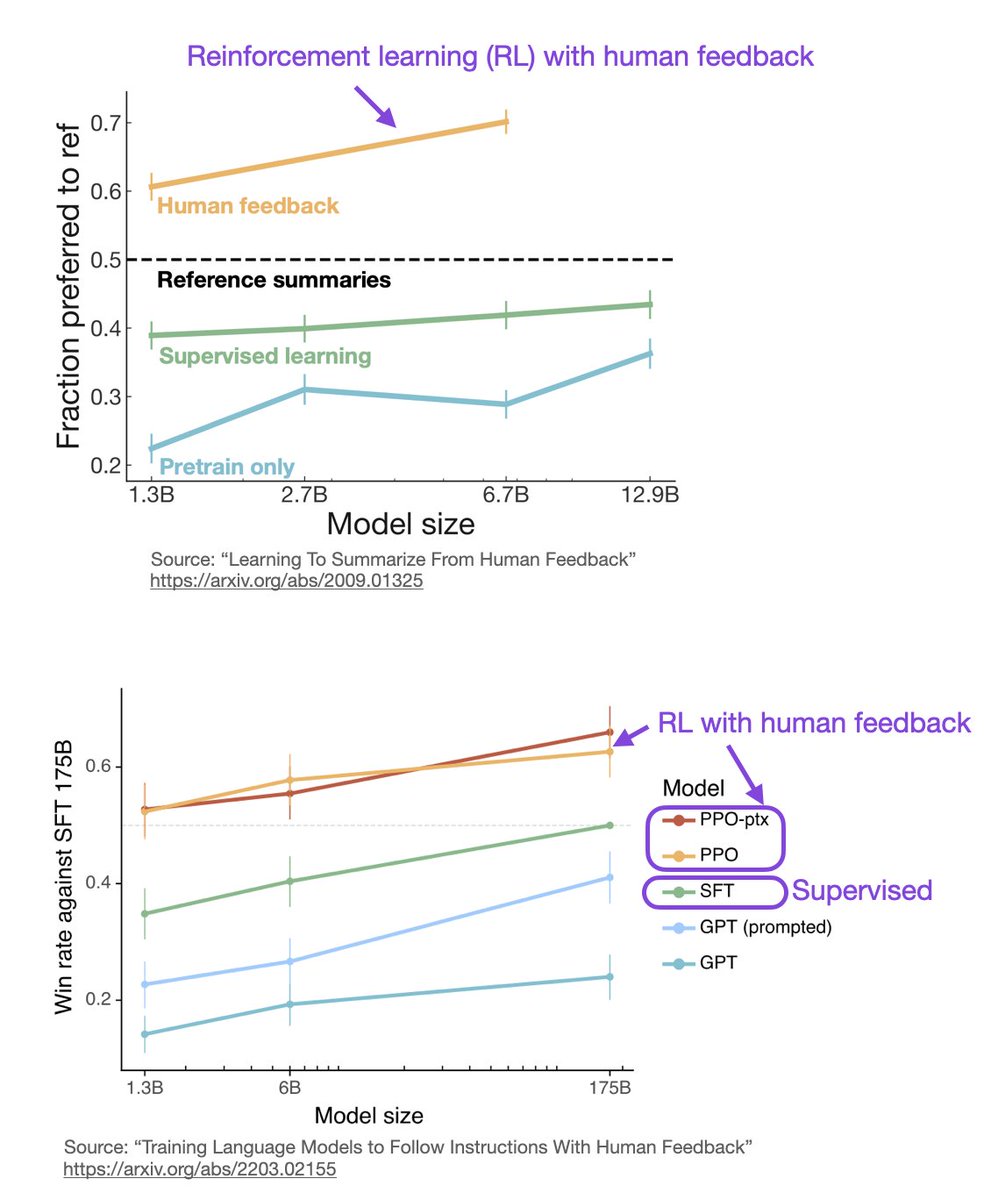 View Tweet
View TweetReason 5). It’s not either SL or RLHF; InstructGPT & ChatGPT use both! The combination is key. ChatGPT / the InstructGPT paper (https://t.co/cHpi3Wrbwb) first finetunes the model via SL and then further updates it via RL. [10/10]
 View Tweet
View Tweet
